Share Article

Salam Qadir
Product & Growth Lead

Discover how schema markup improves AI search visibility in ChatGPT, Perplexity, and Google AI Overviews, and why most sites still get it wrong.
Schema markup is the structured data layer that tells search engines and AI systems exactly what your content means, not just what it says.
Despite that, only 12.4% of registered domains implement any structured data at all, and among the sites that do, fewer than a quarter pass validation cleanly.
The Honest Starting Point: What Google Actually Says About Schema and AI
Before getting into tactics, it's worth settling a question that most articles on this topic skip entirely: does Google require schema markup to appear in AI Overviews or AI Mode?
No. Google's own AI Features documentation states this directly: "There's also no special schema.org structured data that you need to add" to appear in AI Overviews or AI Mode. The same documentation confirms both features rely on standard Search eligibility and use a technique called query fan-out, issuing multiple related searches across subtopics before generating a response.
That single sentence from Google has created a real split in how the SEO industry talks about schema in 2026. Some practitioners read it as proof that schema doesn't matter for AI visibility at all.
Others point to consistent correlational data showing schema-rich pages get cited more often, and conclude schema is essential. Both groups are working from real evidence. The reconciliation is straightforward once you separate two different claims:
Schema is not a gate. Google does not block ungated pages from AI Overviews for lacking structured data, and you do not need new markup formats invented specifically for AI to be eligible.
Schema is a differentiator. Among pages that already clear the relevance and quality bar, schema-marked pages get selected as citation sources more consistently than unmarked pages, because structured data reduces the ambiguity an AI system has to resolve before it can cite something with confidence.
This guide treats that distinction as the foundation for everything else, because conflating the two leads to two equally bad outcomes: either skipping schema entirely because "Google said it's not required," or treating schema as a magic switch that guarantees citations regardless of content quality. Neither is accurate.
What the Actual Research Shows (And Where It Disagrees)
Schema's relationship to AI visibility is one of the few areas in SEO right now where the data genuinely conflicts, depending on who ran the study and what they measured. Both sides deserve a fair hearing.
The case for measurable impact:
A 2026 industry analysis found content with complete Tier 1 schema saw up to 40% more AI Overview appearances.
Pages with FAQPage markup are reported to be 3.2x more likely to appear in Google AI Overviews compared to pages without it.
BrightEdge research found sites implementing structured data alongside FAQ blocks saw a 44% increase in AI search citations.
An arXiv paper published March 11, 2026 found JSON-LD enriched with agent-optimized entity pages lifted retrieval-augmented generation accuracy by 29.6% in standard pipelines and 29.8% in agentic pipelines.
An analysis cited by AnswerManiac found 81% of pages cited by AI assistants use at least one core schema type.
The case for caution:
OtterlyAI ran a controlled three-month experiment (December 2025 to March 2026) implementing schema across its own site and tracking citations across seven AI platforms: ChatGPT, Google AI Overviews, Google AI Mode, Perplexity, Microsoft Copilot, Gemini, and Claude. Their conclusion: "There is no isolated connection that Schema Markup directly caused an increase in AI visibility on ChatGPT." Gemini was the only platform that could fetch the schema directly when asked. The only consistent gains appeared in Google AI Overviews and classic SERP features, and even those gains were described as minimal.
A December 2024 study from Search Atlas, reported by Search Engine Land, found no correlation between schema markup coverage and citation rates. Sites with comprehensive schema didn't consistently outperform sites with minimal markup.
John Mueller of Google confirmed structured data doesn't directly influence ranking; its effect comes through improved user engagement and clearer semantic understanding, both of which can indirectly support AI visibility.
What this actually means for your strategy: treat schema as infrastructure that removes a specific failure mode (ambiguity about who you are and what your content represents), not as a lever you pull to directly cause more citations.
The brands getting cited consistently in 2026 pair schema with genuine topical authority, fresh content, and entity consistency across the web. Schema alone, bolted onto thin or low-authority content, will not move your AI visibility numbers. This is also the conclusion of Search Engine Land's analysis: "Schema markup is infrastructure, not a magic bullet."
How AI Systems Actually Process Your Page
AI systems don't read a page the way a person does. ChatGPT, Perplexity, Gemini, and Google's AI features parse raw text and attempt to extract meaning, identifying entities, attributes, and the relationships between them. Structured data hands them an explicit answer instead of forcing inference: this is an organization, this person wrote this article on this date, this is a question and this is its answer.
Each platform uses that structured layer differently, which matters when you're deciding what to prioritize.
Platform | How It Retrieves Content | What It Weighs Most |
|---|---|---|
ChatGPT Search | Crawls content alongside Bing's index | FAQPage and Article schema for conversational answers; Organization schema to attribute claims to a specific brand |
Perplexity | Real-time crawling against a 200 billion+ URL index, with nearly half of top citations coming from Reddit | FAQPage, Organization, and Product schema for its footnoted citation format; community presence matters as much as schema |
Google AI Overviews / AI Mode | Standard Search eligibility plus query fan-out across subtopics | No special schema required for eligibility, but prefers schema-marked pages when ranking citation candidates among already-eligible results |
Gemini | Native multimodal processing across text, image, and video | The only platform in OtterlyAI's experiment confirmed able to fetch schema directly when asked |
Claude | Emphasizes research-backed, multi-perspective content | Prioritizes proper citations and credible sourcing over structural markup alone |
One nuance worth being precise about: OAI-SearchBot is the user agent responsible for ChatGPT's real-time search retrieval, separate from GPTBot, which is used for model training. Blocking OAI-SearchBot in your robots.txt opts you out of appearing in ChatGPT's search features entirely, regardless of how good your schema is.
Check this before doing anything else; you can validate your current configuration with a robots.txt validator or generate a clean one with a robots.txt generator if you haven't configured this properly yet.
Schema also has a hard limit that no implementation can work around: it enhances visible content, it does not replace it. Schema-only content, meaning information that exists in your JSON-LD but never appears in the visible HTML, fails extraction across every major AI platform tested. Everything that matters needs to be readable on the page first. Schema clarifies what's already there; it doesn't manufacture content that isn't.
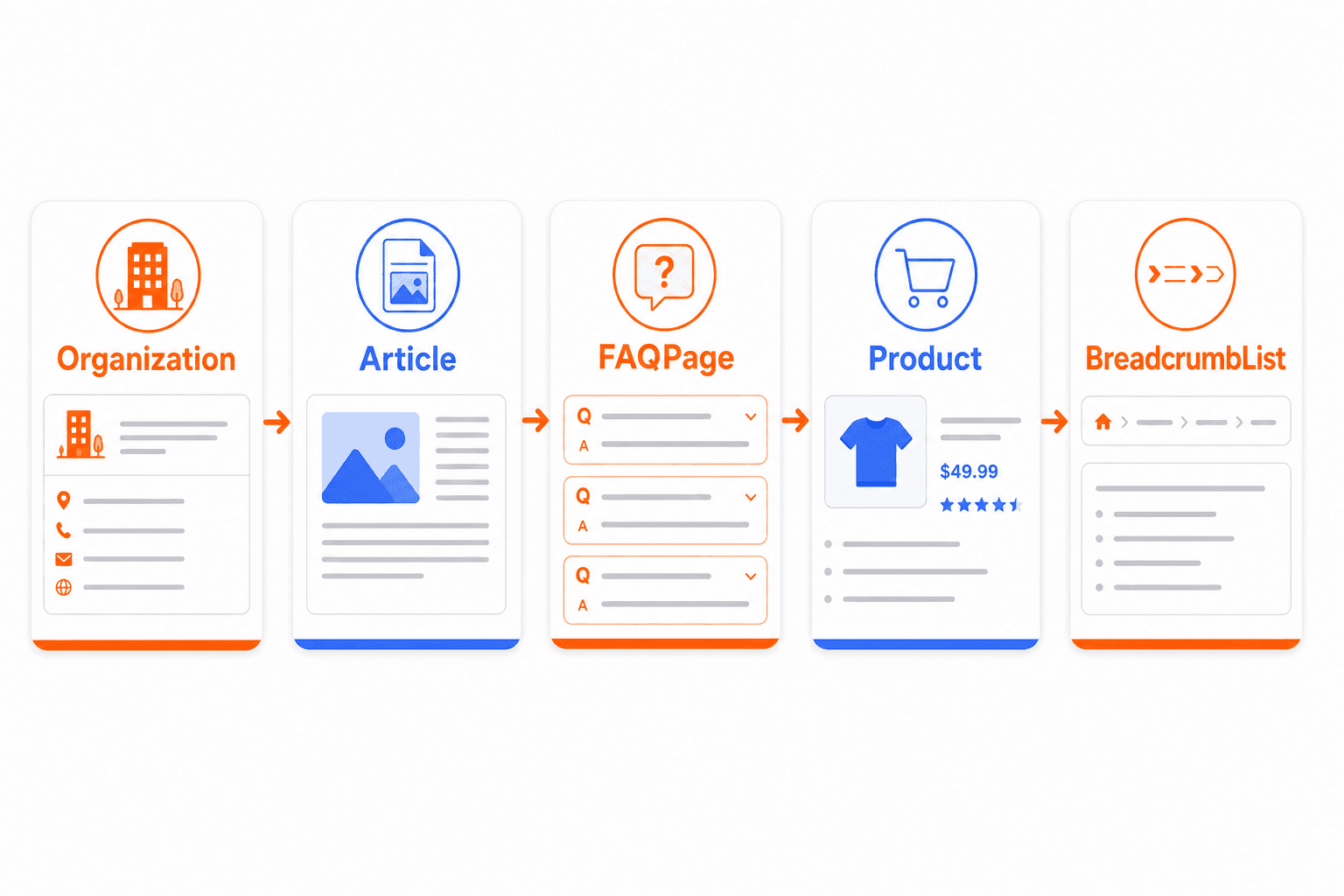
The Schema Types That Actually Matter for AI Visibility
Not every schema type carries equal weight. The five below consistently show up across the research as the highest-leverage types for AI citation, because they each resolve a specific category of ambiguity.
Schema Type | What It Tells AI Systems | Primary AI Visibility Benefit |
|---|---|---|
Organization | Name, industry, founding date, social profiles, official URL | Resolves entity identity; lets AI systems attribute statements to your brand with confidence |
Article / BlogPosting | Author, publisher, publish date, headline, content classification | Encodes E-E-A-T signals and supports accurate citation attribution |
FAQPage | Discrete, structured question-answer pairs | The single highest-citing format; mirrors how AI systems already generate question-driven answers |
Product / Service | Name, price, availability, brand, ratings | Supports shopping citations, comparison features, and commercial recommendation surfaces |
BreadcrumbList | Site hierarchy and content relationships | Gives AI systems context for where a page sits within your broader topical structure |
Example: Organization Schema
Example: Article Schema
Missing the author property, or linking it to an unnamed or generic entity, eliminates the E-E-A-T signal AI systems weight heavily when choosing which sources to trust. Every article should have a named author connected via sameAs to a real, verifiable profile.
Building this correctly by hand across dozens of posts is tedious and error-prone; a dedicated Article schema generator handles the required fields, tracks completeness live, and gives you a SERP preview before you publish, which removes most of the manual mistakes covered in the next section.
Example: FAQPage Schema
FAQ schema best practices worth following strictly: every question should reflect something a real user actually asks, answers should be complete but concise (two to three sentences), the questions and answers must also appear as visible text on the page, and most implementations perform best with five to ten questions rather than padding the count.
You can generate validated FAQ schema directly with Keytomic's FAQ schema generator rather than hand-writing JSON-LD and risking a malformed mainEntity array.
A Note on FAQ Rich Results Specifically
Google restricted FAQ rich results in standard search results to government and health authority sites in August 2023. If you're implementing FAQPage schema expecting the old visual FAQ dropdown in regular SERPs, that visual feature is gone for most businesses, and our own breakdown of why Google removed FAQ rich results covers exactly what changed and why. What didn't go away is AI citation value. The schema that lost its visual SERP placement became more valuable for generative answer extraction, because ChatGPT, Perplexity, and AI Overviews still actively crawl and cite FAQ structured data even though Google stopped rendering it as a rich snippet.
Beyond the Big Five: What's New in 2026
Schema.org released version 30.0 on March 19, 2026, introducing the Credential and Error types. The Credential type expanded beyond educational degrees to cover professional certifications and regulated qualifications, the exact kind of domain credential AI models increasingly want to verify before treating a source as an authoritative expert.
A few supplementary types worth knowing if you want to go further than the core five:
Dataset and DefinedTerm encode proprietary data assets and original terminology, which AI models cite as primary sources when summarizing a topic. If you have data nobody else has published, this is how you make it citable infrastructure.
ItemList encodes ranked or ordered lists, which get cited directly as ranking sources for "best of" and "top N" style queries.
ImageObject with caption, creditText, and explicit copyrightHolder properties turns images into multimodal citation candidates that Gemini and ChatGPT vision can surface alongside text citations.
Speakable signals voice-optimized content to AI assistants handling spoken queries.
Most sites don't need these immediately. Get the core five (Organization, Article, FAQPage, Product or Service, BreadcrumbList) implemented and valid first. These supplementary types matter most for sites with genuinely proprietary data or strong visual content to protect and surface.
Why Most Sites Still Skip Schema (Or Get It Wrong)
The gap isn't awareness. Most SEO professionals already know structured data matters. The real causes are more specific.
Nobody owns it cleanly. Schema implementation tends to fall into the gap between the SEO team, the development team, and CMS configuration. Without a clear owner, it either gets deprioritized indefinitely or delegated to a plugin that generates something technically present but factually wrong.
The data backs this up precisely. A 2026 audit of 5,000 production sites found that 71% deploy at least one schema type, but only 22% pass Google's Rich Results Test cleanly across every type detected. That 49-point gap represents sites with schema technically present that are getting nothing useful from it, because the markup is broken, incomplete, or contradicts the visible page.
Teams absorbed half the FAQ story. Many concluded FAQPage schema isn't worth the effort once Google restricted FAQ rich results in 2023. They got the SERP-visibility part right and missed that the same markup became more valuable for AI citation extraction, not less.
There's no maintenance workflow. Schema gets written once during a redesign or initial build, then pages change, content gets updated, new posts go live, and the structured data quietly falls out of sync with what's actually on the page. AI systems actively check for this kind of mismatch. A schema claiming a January publish date on a page that visibly shows a different date is treated as a credibility problem, not a harmless inconsistency.
Common Schema Mistakes That Actively Hurt You
Invalid JSON-LD and missing required properties. This is the most frequent technical failure: required properties missing, wrong data types, or templated schema blocks that don't update when the page content changes. Run every page through Google's Rich Results Test and the Schema.org Validator before publishing, not after.
Schema that contradicts visible content. If your Article schema says "Published: January 2026" but the visible page shows a different date, or your Product schema lists a price that doesn't match what a user actually sees, that's not a missed opportunity, it's an active trust problem. AI systems and search engines both treat this kind of mismatch as a credibility signal working against you. The rule from Google's own structured data guidelines is direct: structured data must be a true representation of the page content.
Overstuffed or irrelevant markup. Declaring a blog post as both a Product and a Course because a template added both creates conflicting entity signals instead of clarity. Use only the schema types that genuinely describe what the page is, and make sure every populated property has a corresponding visible element on the page.
Stale schema after content updates. If you refresh an article's statistics, examples, or claims, but never touch the dateModified field, you're sending a freshness signal that contradicts your own content update. This is one of the most common and easiest-to-fix mistakes; pair every meaningful content refresh with a schema review, not just a content review.
A Schema Implementation Workflow That Actually Holds Up
Audit what's already live. Run your top pages through the Rich Results Test and the Schema.org Validator. Don't assume your CMS plugin is generating clean output; verify it.
Prioritize the core five schema types (Organization, Article/BlogPosting, FAQPage, Product/Service, BreadcrumbList) before expanding into supplementary types like Dataset or Credential.
Connect everything via
@id. The more useful 2026 pattern isn't isolated Organization or Article markup, it's a connected graph where your Person, Organization, and Article schemas reference each other through shared@idvalues, so AI systems can resolve the same entity consistently across every page.Match schema to visible content exactly. Every date, author name, and price in your JSON-LD must match what a human sees on the page. No exceptions.
Validate before every publish, not as an occasional audit. Build this into your publishing checklist the same way you'd check for broken links; a broken link checker and a canonical URL checker belong in the same pre-publish routine as your schema validation.
Set a quarterly audit cadence at minimum, and re-validate immediately after any content change that could affect JSON-LD: new pricing, author changes, structural template updates, or substantive rewrites.
Measure citation frequency, not rich result impressions. The old success metric (FAQ rich result impressions in Search Console) doesn't apply anymore for most sites. The new metric is whether ChatGPT, Perplexity, and AI Overviews are actually citing you, which means running your own brand and category queries against these platforms on a recurring basis to check.
Schema Is One Layer in a Larger AI Visibility System
Everything covered here sits inside a broader discipline some practitioners call generative engine optimization, or GEO. Schema resolves entity ambiguity.
It does not replace the other signals AI systems weigh: topical authority built through consistent, accurate publishing, genuine freshness (not just an updated timestamp but actually updated information), and entity consistency across the wider web, not just your own domain.
If your site ranks well on Google but you're still seeing little to no presence when you ask ChatGPT or Perplexity questions in your category, schema is worth auditing, but it's rarely the only fix.
Our guide to closing the AI search brand gap and our LLM citations checklist cover the adjacent signals (content structure, third-party corroboration, indexing) that schema alone can't solve. If your content is published but Google still isn't indexing it properly, that's frequently a separate, more fundamental problem worth ruling out first, covered in why Google isn't indexing your AI content.
For agencies managing schema and AI visibility across many client sites at once, or marketing and SEO teams trying to keep structured data in sync with a fast publishing schedule, the coordination problem described earlier (nobody owns it cleanly) tends to multiply with every additional site.
Keytomic's agency, SEO team, and marketing team workflows build schema generation into the publishing pipeline itself rather than treating it as a separate technical task someone has to remember to do after the fact. Founders managing this solo can see the founder-focused workflow here.
Frequently Asked Questions
Is schema markup required to appear in ChatGPT or Perplexity answers?
No. Schema is not a requirement for citation eligibility on any major AI platform, including Google's own AI Overviews and AI Mode, per Google's official documentation. It does, however, measurably improve the odds of citation among already-eligible content by reducing the ambiguity AI systems have to resolve before confidently attributing a claim to your brand.
Does schema markup directly affect Google rankings?
No, not as a direct ranking factor. Schema supports rich result eligibility, entity understanding, and AI Overview citation likelihood, all of which can influence traffic indirectly through better SERP features and AI search placement, but Google has confirmed structured data itself is not a ranking signal.
Which schema types should most businesses prioritize first?
Start with Organization, Article or BlogPosting, FAQPage, and BreadcrumbList. These four cover entity identity, content classification and authorship, Q&A extraction, and site hierarchy, which together address the majority of AI citation use cases for most content-driven and B2B sites. Ecommerce sites should add Product schema to this list immediately.
How do I validate schema markup before publishing?
Use Google's Rich Results Test for SERP feature eligibility and the Schema.org Validator for raw syntax accuracy. Run both after any content or template change that could affect your JSON-LD output, not just during an occasional audit.
Why did my FAQ schema stop showing rich results in Google search?
Google restricted FAQ rich results to government and health authority websites in August 2023. If you're a general business site, that specific visual snippet is no longer available to you regardless of how well your FAQ schema is implemented. The schema itself remains valuable for AI citation purposes; it simply no longer produces the dropdown rich result in standard blue-link search.
How often should schema markup be audited?
Quarterly at minimum, and immediately whenever content changes substantively: pricing updates, author changes, new service descriptions, or any structural template modification that could alter what your JSON-LD actually outputs versus what the page visibly shows.
Can schema markup alone fix poor AI search visibility?
No. Multiple controlled studies, including a three-month, seven-platform experiment by OtterlyAI and a separate analysis from Search Atlas, found no reliable direct correlation between schema coverage alone and AI citation volume. Schema works as a supporting signal on top of genuine topical authority, content freshness, and entity consistency, not as a standalone fix for weak or thin content.
What is the difference between schema markup for traditional SEO and for AI search?
Traditional SEO uses schema primarily to earn visual rich results in Google's blue-link search results: star ratings, FAQ dropdowns, event listings. AI search uses the same underlying markup differently, as a machine-readable confidence signal that helps ChatGPT, Perplexity, and AI Overviews verify entity identity, authorship, and content type before deciding whether to cite a source. The format is identical; the role it plays in the retrieval and citation decision is different.
FREE AI Visibility Audit

Is Your Brand Visible in AI Searches?
Free AI Visibility Audit → See where you appear (and where competitors appear).






